Taverna's support for SOAP based web services has been enhanced. This enhancement in particular relates to the support for web services that require and/or return data encapsulated within a complex data structure, in XML format. This support covers Document/literal based services, and to a fair extent RPC/encoded based services.
As in previous versions of Taverna, web services are added to the list of available services by providing the location of a Web Service Description Language (WSDL) to the WSDL Scavenger. It inspects the file and extracts all the information about the data types required to invoke the services described by the WSDL. For WSDL's that describe very complex data structures this can sometimes take a few seconds depending on network speed.
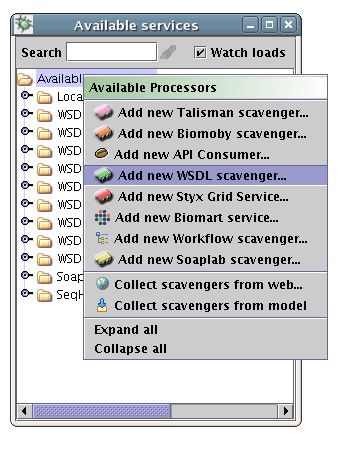
Once the WSDL has been added to the list of services, processors can be added to the workflow just like any other processor. When expanding the list of inputs, or outputs, to the services, those that require a complex data structure will be described as having a mime type of 'text/xml' (or l'(text/xml') if it expects an array of complex data types).
For many web services it is possible to provide the data directly by providing the XML, but this requires the user to have previous knowledge of the structure of the data that the service expects. For this reason, 'XML splitters' are provided which interrogate the data structure and present to the user the internal data elements. XML splitters resolve the XML data structure by a single level, revealing child elements that can be either base types or further complex types themselves. Child elements that are complex can be split further, and so on until all the required elements are revealed.
For inputs, values are then assigned in the standard manner, and when the workflow is run the splitters reconstruct the XML to then be used when invoking the service.
For outputs, the values can be passed on to downstream processors in the standard manner, and are extracted from the XML resulting from invoking the service. In both cases, arrays are handled by the standard iteration's mechanism.
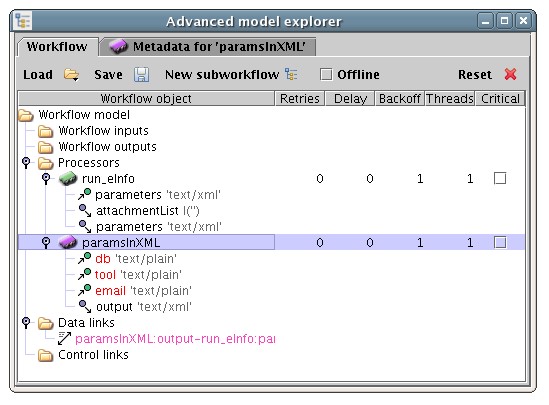
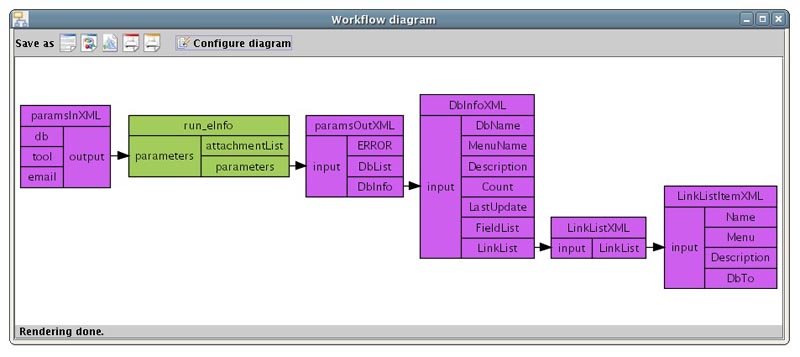
For example, the NCBI service run_eInfo input 'parameters' expects data according to the following structure:
<eInfoRequest> <db/> <email/> <tool/> </eInfoRequest>
An XML splitter is added upstream by right-clicking on the parameters node and selecting 'Add XML splitter', or 'Add XML splitter with name' to explicitly provide a name.
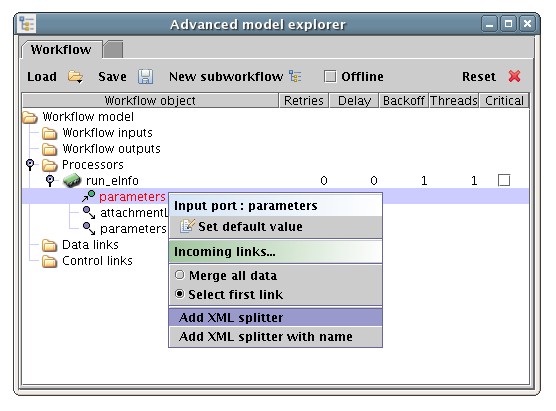
The upstream processor will then expose the inner element db,email and tool, that can be set normally. Its output port will be automatically linked to the input port it is splitting.
This service also returns a more complex data structure, also called parameters, a simplified version of which looks like:
<eInfoResult>
<ERROR />
<DbList>
<DbName />
</DbList>
<DbInfo>
<DbName />
<MenuName />
<Description />
<Count />
<LastUpdate />
<FieldList>
.
.
.
</FieldList>
<LinkList>
.
.
.
</LinkList>
</DbInfo>
</eInfoResult>So, an output splitter can be added just as with an input splitter. As with an input splitter, its input port is automatically linked the output port it is splitting.
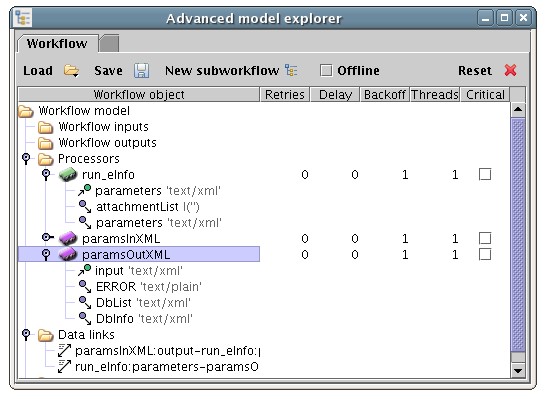
Because the inner elements DbList and DbInfo are also complex, they can be expanded further. In this case DbInfo is expanded into its inner elements DbName, MenuName, Description, Count, LastUpdate, FieldList and LinkList. FieldList and LinkList are also complex and be expanded even further and so on.
Often, inner elements of complex type are optional and there is no way until the workflow has been run whether these elements are present in the output or not. If an element is missing, but has been defined by an XML splitter then its value with be set to either an empty string, or an empty tag if it is complex. So if in the above example, ERROR was missing its value would be set to an empty string. If DbInfo was missing it would be set to <DbInfo />. In this way missing elements will ripple through to further splitters that will behave in the same way preventing the workflow from failing.
A cyclic reference is a child element that contains elements that refer back to one of its ancestor element (for example if in the previous example DbInfo contained an element that refered to eInfoResult). Because Taverna resolves data structures into a single XML structure, cyclic references within the structure will cause Taverna to fail. For this reason, when an output splitter is created that relates to a data structure that contains cyclic references, a warning is provided to the user.

The user can still continue to create and run the workflow, as its possible the returned data will not contain the offending elements, but should it do so it is likely the workflow will fail.