Table of Contents
SCUFL is an acronym standing for 'Simple Conceptual Unified Flow Language'. This section describes some of the features of this language which distinguish it from the various alternatives such as the Business Process Enactment Language (BPEL).
Iteration in this context is the repeated application of a process to multiple data items. An example might be the processing of a set of genomic sequence data files through a GC concentration analysis resulting in a set of concentration figures. In a conventional imperative language such as PERL this would be accomplished by explicitly creating a block in the code over which the execution loops until some condition is satisfied, a typical 'while <condition> do <something>' type structure, the condition most often being 'there are items left to process'. Taverna does not have this kind of construct, instead it provides a system closer to map functions in languages such as ML. While this might sound complex and foreign to most users it should be relatively intuitive to actually use.
Whereas an explicit iteration construct requires the user to code the iteration into their script with specific commands and code structures, Taverna's implicit iteration framework requires (in the simplest cases) no additional work at all. The user simply connects an output containing a collection of items into an input which consumes a single item of the same type. In the previous example the user might have access to a processor which consumes a single DNA sequence and emits a single floating point value corresponding to the GC concentration over that sequence. To iterate over a set of sequences the user simply connects the set of sequences into the same input - Taverna detects that there is a mismatch of this kind and repeatedly runs the GC concentration analysis over each sequence in the input set. As the normal output is a single floating point value the new output is a list of such values, the first corresponding to the first input sequence, the second to the second and so on. Of course, this iteration will tend to 'bubble down' the workflow as a result, if the next processor expected a single GC concentration number it will itself be run repeatedly on all results.
The corresponding wrapping logic also exists, if a processor expects a list of sequences and the user connects it to an output which provides a single sequence the single sequence will be wrapped up in a single item list.
The behaviour in the above case should be self explanatory, however, there are also cases where multiple inputs have mismatched cardinalities; these are more complex and may require some level of configuration before they behave as desired.
The default behaviour in these cases is to iterate over all combinations of input values. This could be exactly what is intended, for example an all against all sequence distance metric computation would be simple to implement within a workflow assuming the existence of a processor capable of returning a single pair wise distance, the user would connect a list of sequences to both inputs and the iteration system would iterate over all combinations. As there are two lists being iterated over in this case the output will be a list of lists of results, reasonable enough given that the all against all distance table is two dimensional.
There are cases, however, where this behaviour is not desirable. Consider a processor which had as input a sequence and a list of features corresponding to matches within PFam or similar and which then returned an image showing the location of these features on the sequence. If this processor were invoked with a list of sequences and a list of lists of features (so one dimension higher than expected) in the manner described above the result would not make sensel, the output would be a list of lists of images where all sequences had all features applied to them. The first item for one input is related to the first item in the other input and not to the second or subsequent ones so iterating over all combinations of inputs is meaningless. A preferable iteration strategy would be to pick the first item from each input list, run the process on that then pick the second from each list and so on to produce a list (as opposed to a list of lists) of output images. This would preserve the inherent relationship between the input items. Taverna allows this to be specified using the iteration strategy editor within the AME, accessed by selecting a processor node then opening the newly enabled tab.
The following image shows the iteration strategy editor for a simple processor which concatenates two strings together. By selecting the 'Create Iteration Strategy' button the user has created an explicit iteration strategy initialised to the default 'all against all' behaviour:
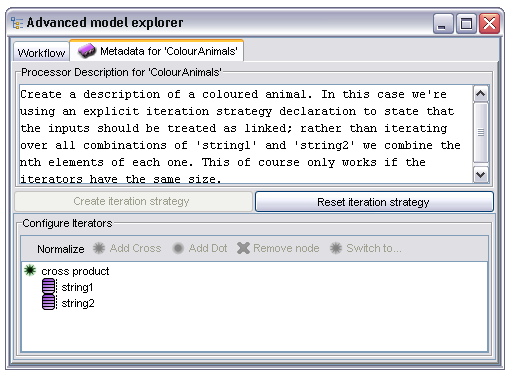
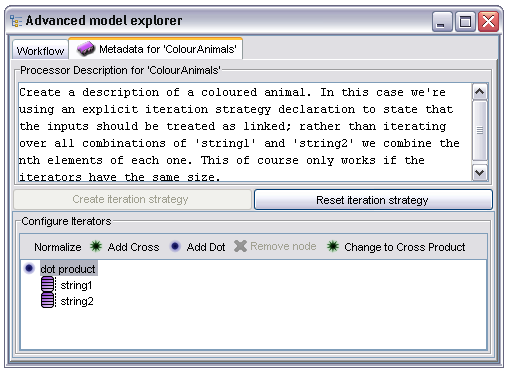
The iteration strategy is displayed as a tree. The leaf nodes in the tree correspond to the individual inputs to the processor, in this case 'string1' and 'string2'. Non leaf nodes represent the different ways of combining the input iterators and the 'cross product' node represents the 'all against all' combination of its child nodes. In order to change the behaviour to one where the inputs are consumed in the alternative 'first against first, second against second...' style the user selects the 'cross product' node and clicks on the 'Switch to...' button (which becomes the 'Switch to dot product' when the node is selected) to change it to a 'dot product' node:
Iteration strategies can potentially combine multiple different types of dot and cross product nodes, a processor which consumed three strings might have an iteration strategy defining the input to be the combination of all values of string1 with the dot product of all pairs of values from string2 and string3. Nodes may be dragged around within the iteration strategy editor, to drop a node onto a dot or cross product node as a child the user must flick the mouse to the right before dropping the node, an arrow will appear to indicate the gesture recognition. In the case below a new cross product has been added and the 'string2' leaf is being moved into it as a child, the mouse being flicked to the right indicating that the intent is to create a child node rather than drop as a sibling:
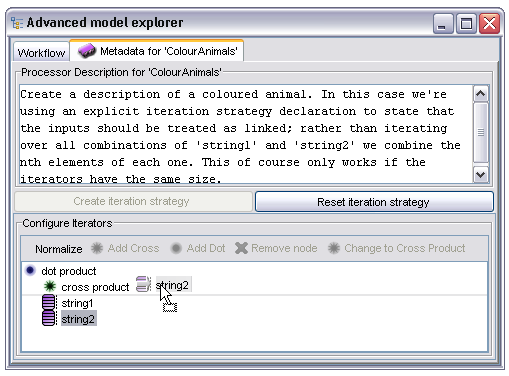
In the image above the iteration strategy is not normalised; the cross product of a single node is identical to the node itself. If the user selects the 'Normalise' button the iteration strategy will be reduced to its simplest form without any change in behaviour.